FAQ
The following is a break down of common questions about OPAL by categories.
Data updates
What is the difference between initial data load (baseline) and follow-on updates ?
A baseline update is used to bring an OPAL-client from a no-state (first connect, reconnect) status, to a basic ready state.
Follow on data update triggers continue to update the client state on top of a baseline.
Data fetchers are used both to load the initial baseline data as indicated by OPAL_DATA_CONFIG_SOURCES, and for subsequent update (or delta changes) as part of an update event
The instructions in OPAL_DATA_CONFIG_SOURCES should enable a client to reach the current needed relevant state at any point.
What is the difference between triggering an update event, and fetching the data for the event ?
Triggering an update is done by calling the REST API on the opal-server, letting OPAL know there's an update. (You can also publish events via the backbone pubsub (e.g. Kafka) ) The update will propagate between OPAL servers and then be sent to the relevant subscribing clients according to the topics it has. Once a client receives an update from a server, it will always use a data-fetcher to fetch the data it needs (unless the data is part of the update itself [which is less recommended]) according to the instructions in the event. The event via the config field also indicates which type of data-fetch-provider the client should use.
How does OPAL send the data itself for updates?
Instead of sending the data itself, OPAL sends instructions to the subscribing clients (per-topic) on how to fetch the data directly. Note: since OPAL 0.3.0 you can also send data on the pub-sub event (but we don't recommend that as a default) Note: you can teach OPAL-clients to fetch data from different sources by writing a data-fetch-provider - small python modules that are easy to create
How are data update events handled for the interim period between an OPAL-client starting and it getting the baseline data?
Once connected, the OPAL-client will start tracking data update events that you send and handle them. It does so from the start even before getting the first base data - and will process the events in order - so you don't need to track them specifically.
Does the OPAL-client fetch the update messages from the OPAL Server and re-run them after it builds the initial state?
The client does not re-run, but more correctly spins tasks to update as events come, and processes them once possible. Usually loading the client is pretty fast, so we haven't encountered issues here. In general this is not a pure OPAL problem but a general multi process read/write sync challenge. If it is an issue for you, We can suggest a few options:
- Create a clone source where clients get their base data set, instead of working directly with the rapidly changing data source (this can be another OPA+OPAL instance for example - almost like a master node)
- Temporarily lock access to the database for writing until the client is ready - (reader/writer lock pattern)
How can I plug data into OPAL?
OPAL is extensible, its plugin mechanism is called fetchers. With them you can pipe data into OPA from 3rd party sources. You can learn more about OPAL fetchers here or simply try to use an existing one.
Which is the better mechanism to use for realtime? OPA http.fetch() or an OPAL Client fetch provider?
Unless the data source is a very stable ingrained service (part of the core system), and the queries to it are simple (low data volume and frequency) - We would always recommend the data fetcher option. It decouples the problem of loading data from querying the policy.
How can we trigger the OPAL data fetch from within Rego?
First of all, you are not really supposed to trigger it from Rego - the idea is usually for it to be async and decoupled from the policy itself. Instead, the data source or the service mutating it are the ones sending the triggers to OPAL, handling the updates in the background - independent of any policy queries.
That being said, you can technically use http.send() to trigger an update - as the API trigger is restful.
Kubernetes
If I'm using OPAL just for Kubernetes level authorization, what benefits do I get from using OPAL compared to kube-mgmt?
OPAL solves the most pain for application-level authorization; where things move a lot faster than the pace of deployments or infrastructure configurations. But it also shines for usage with Kubernetes. We'll highlight three main points:
-
Decoupling from infrastructure / deployments: With OPAL you can update both policy and data on the fly - without changing the underlying deployment/ or k8s configuration whatsoever (While still using CI/CD and GitOps). While you can load policies into OPA via kube-mgmt, this practice can become very painful rather quickly when working with complex policies or dynamic policies (i.e. where someone can use a UI or an API to update policies on the fly) - OPAL can be very powerful in allowing other players (e.g. customers, product managers, security, etc. ) to affect policies or subsets of them.
-
Data updates and Data distribution- OPAL allows to load data into OPA from multiple sources (including 3rd party services) and maintain their sync.
-
OPAL provides a more secure channel - allowing you to load sensitive data (or data from authorized sources) into OPA.
- OPAL-Clients authenticate with JWTs - and the OPAL-server can pass them credentials to fetch data from secure sources as part of the update.
It may be possible to achieve a similar result with K8s Secrets, though there is no current way to do so with kube-mgmt. In addition this would tightly couple (potentially external) services into the k8s configuration.
Networking & Connectivity
Does OPAL handle reconnecting ?
OPAL-clients constantly try to reconnect to their opal-servers, with an exponential back off.
Once a client reconnects it will follow the data instructions in OPAL_DATA_CONFIG_SOURCES to again reach a baseline state for data.
How does OPAL handle data consistency / changes ?
Short answer: with Speed. The pub/sub web socket is very lightweight and very fast - usually updates propagate within few milliseconds at worst. The updates themselves (by default) are also lightweight and contain only the event metadata (e.g. topic, data source), not the data itself. Hence OPAL-clients are aware of changes very quickly, and can react to the change (within their policy or healthchecks) even before they have the full data update.
Can I run the OPAL-server without OPAL_BROADCAST_URI ?
Yes. This is mainly useful for light-workloads (Where a single worker is enough) and development environments (where you just don't want the hassle of setting up a Kafka / Redis / Postgres service).
Since server replication requires broadcasting, make sure that UVICORN_NUM_WORKERS=1 and pod scaling is set to 1 (when running on k8s)
How does OPAL guarantee that the policy data is actually in sync with the actual application state. We get that OPAL server publishes updates to OPAL client but is there error correction in place.
Thanks to the lightweight nature of the OPAL pub/sub channel - clients very quickly learn of changes in the data state even before they have the data itself - this allows the OPAL-clients, their data-fetcher components, their managed OPA instances (OPAL-client stores this state in OPA), and other subscribing services to respond to data change and handle the interim state. The simplest form of here is
- Your Rego policy can use the health state value to make different interim decisions OPAL.
- The OPAL client will continue to try and fetch data the data until it gets it (with exponential backoff).
You can read more about the mechanism here.
How does OPAL handle the situation when an OPA container is restarted or gets out-of-sync with source system ?
Devops, maintenance and observability
Does OPAL provide health-check routes ?
Yes both OPAL-server and OPAL-client serve a health check route at "/healthcheck"
Read more about monitoring OPAL
Does OPAL provide some kind of monitoring dashboard ?
Not yet - we are planing on releasing that as part of another major release of OPAL. If you want early access to those features , or want to contribute to their development - do let us know.| In the meanwhile, you can use something like Prometheus and feed it the /statistics (/tutorials/monitoring_opal) And of course you can use Permit.io which adds many control plane interfaces on top of OPAL.
Security
I'm configuring OPAL to run with a kafka backbone. We have an existing kafka setup using SASL authentication. I can't see any examples for configuring this with authentication. What's the best way to achieve this?
At a glance it seems the current broadcaster Kafka backend doesn't support SASL. You can read more here. Unless there is a way to pass this configuration via URL to the underlying Kafka consumer.
It can be supported without a ton of work (as AIOKafka does support it), but currently the SASL params are not exposed.
I would suggest one of the following:
- You can upgrade the broadcaster code to expose these variables - either as part of the URL, or as env-vars. (If you do please consider contributing this back to the project).
- Use a Kafka proxy to add the needed params - e.g. kafka-proxy.
- Open an issue on our GitHub requesting we do item #1 for you; and we will do our best to prioritize it.
Got a question that is missing from here? checkout our Slack community, it's a great place to ask more questions about OPAL.
Case studies
Handling a lot of data in OPA
Question
I have generated a lot of permission data (e.g. 1.3mln records (or ~150MB)) and it causes the OPAL-client container memory to inflate to more than 2GB, and OPA crashes. Could you please advise what could be done to fix this? I have started the containers with configuration similar to docker-compose-example, with corresponding data config source:
- OPAL_DATA_CONFIG_SOURCES={
"config":{
"entries":[
{
"url":"http://host.docker.internal:8000/permissions.json",
"topics":["permissions"],
"dst_path":"/course_permissions"
}
]
}
}
Loading this data itself causes the OPAL client container to consume 2.3 GBs of memory (according to Docker).
Then I have created a policy file with a single policy that filters the records based on input.userId.
Evaluating that filtering takes random time from 1 minute to 10 seconds, and sometimes (1 time out of 10) crashes the OPA process. See the screenshot for the time difference between request processing.
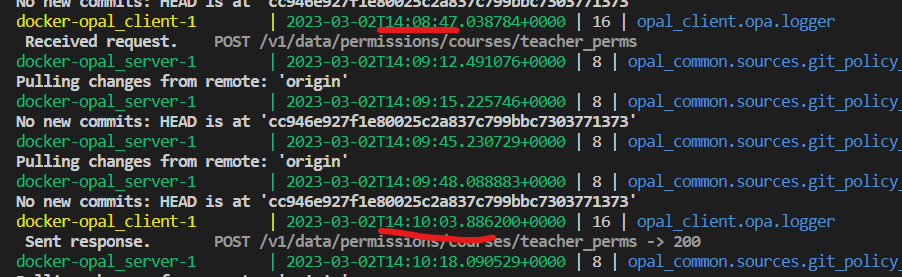
I understand that this might not be a very optimal data structure, but still not really the performance I'd expect.
Answer
These are most likely (>95%) issues with OPA not OPAL, as OPA is running with the OPAL-client container.
OPA is known to bloat loaded data in memory - as it loads it into objects; You can improve that by changing the data schema and policy structure. High volume of data, and inefficient structure will lead to bad performance. A few suggestions to what to try next:
1. Validate that the issue is OPA and not OPAL - you can do so by one of:
- check which process is the one with the extensive memory consumption within the container
- loading the data manually into OPA regardless of OPAL
- Running the OPA agent standalone to the client
2. Check if you actually need all the data - most often the data needed for authorization is a very small subset (often just ids and their relationships)
- you can save a lot of space by minimizing the data
- once you decide on the subset you actually need; you can do so on the fly using a custom data fetcher, or by adding an API service to perform the transformation.
3. Increase the container / machine resource limits (memory / CPU)
4. If you do need all of the data - consider sharding it between multiple OPA agents